
Language models have demonstrated exceptional performance across various real-world applications. However, at contemporary scales, the conventional training method employing standard backpropagation introduces formidable engineering and infrastructure challenges. The difficulty lies in co-locating and synchronizing a large number of accelerators.
In response to this challenge, in a new paper DiLoCo: Distributed Low-Communication Training of Language Models, a Google DeepMind research team presents Distributed Low-Communication (DiLoCo). DiLoCo employs a distributed optimization algorithm that facilitates the training of language models on islands of poorly connected devices, surpassing the performance of fully synchronous models while reducing communication by 500 times.

Drawing inspiration from Federated Learning literature, the researchers propose a variant of the widely-used Federated Averaging (FedAvg) algorithm. They introduce a specific instantiation with a momentum-based optimizer, akin to the FedOpt algorithm. Notably, DiLoCo replaces the inner optimizer with AdamW and the outer optimizer with Nesterov Momentum for optimal performance. This innovative combination effectively addresses the challenges posed by conventional training approaches.
The DiLoCo approach mitigates the aforementioned challenges through three key elements: a) Limited co-location requirements: While each worker requires co-located devices, their number is smaller than the total, easing the logistical burden. b) Reduced communication frequency: Workers need not communicate at each step, but only every 𝐻 steps, potentially in the order of hundreds or even thousands, significantly lowering communication overhead. c) Device heterogeneity: While devices within an island need to be homogeneous, different islands can operate with different types of devices, enhancing flexibility.
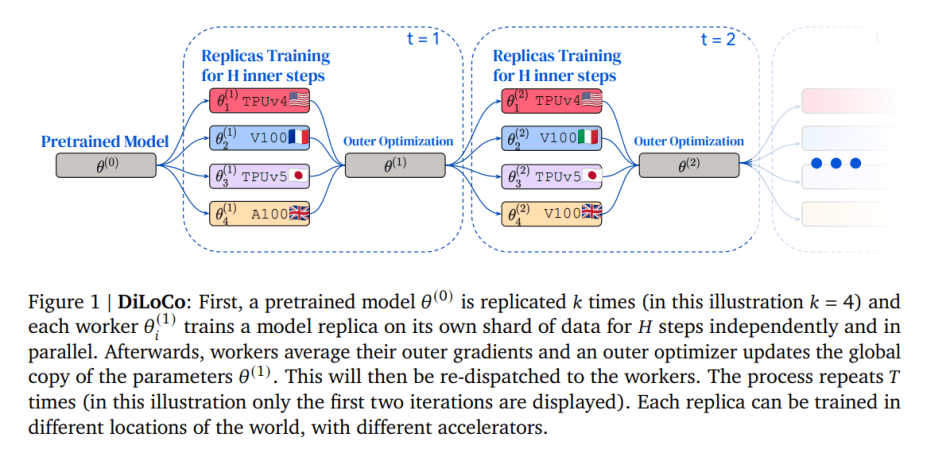

In the DiLoCo training process, a pretrained model 𝜃 (0) is replicated 𝑘 times. Each worker independently and in parallel trains a model replica on its own shard of data for 𝐻 steps. Subsequently, workers average their outer gradients, and an outer optimizer updates the global parameter copy 𝜃 (1), which is then redistributed to the workers. This process repeats 𝑇 times. Notably, each replica can be trained in different global locations using various accelerators.
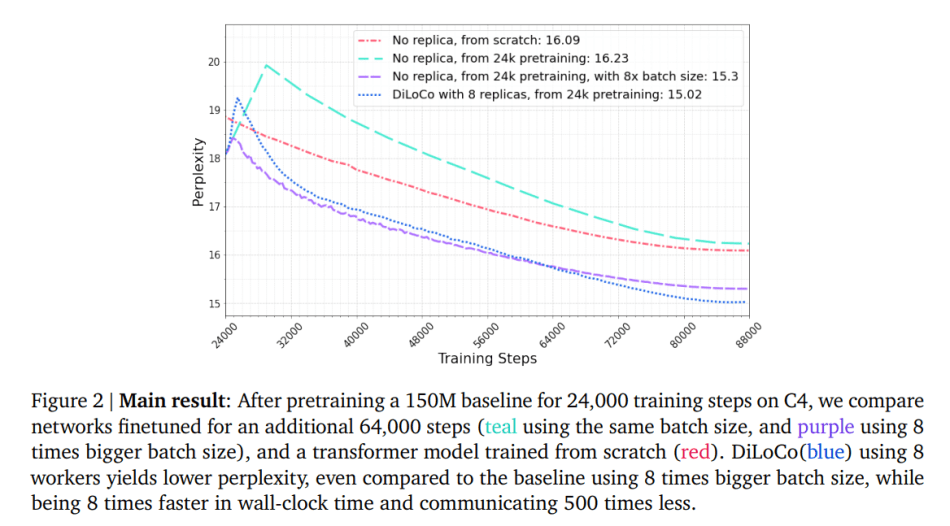
On the widely-used C4 dataset, DiLoCo with 8 workers demonstrates performance on par with fully synchronous optimization while reducing communication by 500 times. Furthermore, DiLoCo exhibits remarkable robustness to variations in the data distribution of each worker and adapts seamlessly to changes in resource availability during training.
In summary, DiLoCo presents a robust and effective solution for distributing the training of transformer language models when multiple machines are available but poorly connected. This innovative approach not only overcomes infrastructure challenges but also showcases superior performance and adaptability, marking a significant advancement in the field of language model optimization.
The paper DiLoCo: Distributed Low-Communication Training of Language Models on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

The importance of DiLoCo as a solution to the four colors and infrastructure challenges associated with training large-scale language models is truly evident.