
In recent times, the growing demand for low-latency requirements in video-based applications, such as video conferencing, webcasting, and cloud gaming, has become increasingly evident. Addressing the need for enhanced real-time streaming video quality and minimizing video defects caused by compression algorithms, the emergence of Online Video Quality Enhancement (Online-VQE) has proven effective.
However, a significant challenge arises as Online-VQE must process high-resolution videos in real-time, ensuring a seamless viewing experience. It is constrained by relying solely on the current and previous frames for inference due to uncontrolled latency caused by waiting for future frames, resulting in potential overall video delays.
To tackle this issue, a groundbreaking paper titled “Online Video Quality Enhancement with Spatial-Temporal Look-up Tables” introduces a novel method, STLVQE. This research, conducted by a team from Tongji University and Microsoft Research Asia, pioneers the exploration of the online video quality enhancement problem and presents the first method achieving real-time processing speed.

The team’s contributions can be summarized as follows:
- Introduction of STLVQE: The team proposes STLVQE as the first online-VQE method achieving real-time processing speed. This approach reduces redundant feature extraction computations by redesigning the propagation, alignment, and enhancement modules of the temporal VQE network.
- Spatial-Temporal Look-up Tables (ST-LUTs): The introduction of a unique ST-LUT structure allows for the comprehensive exploitation of temporal and spatial information in videos, a first-of-its-kind proposal. This innovative approach facilitates efficient extraction of temporal information, simultaneously querying both spatial and temporal dimensions.
- Performance Validation: Extensive qualitative and quantitative experiments on the Compressed VQE benchmark dataset MFQE 2.0 demonstrate that STLVQE achieves a commendable speed-performance tradeoff, showcasing its efficacy in enhancing online video quality.
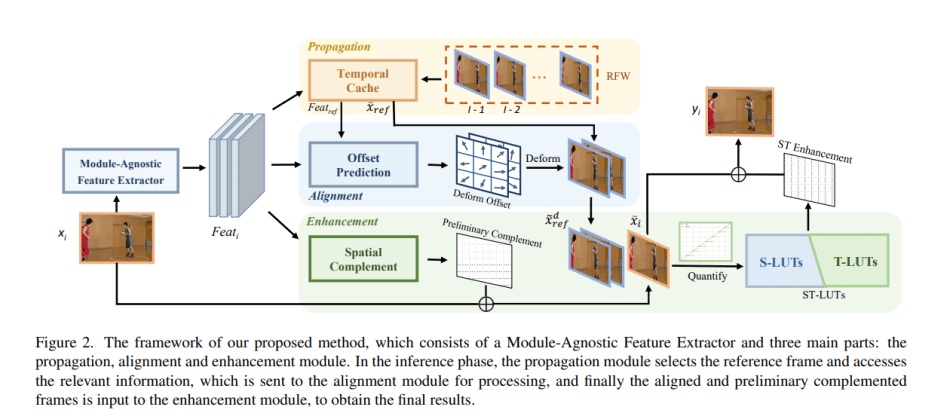
The STLVQE architecture comprises a Module-Agnostic Feature Extractor and three key components: the propagation, alignment, and enhancement modules. During the inference phase, the propagation module selects the reference frame, accesses relevant information, which is then processed by the alignment module. Finally, the aligned and preliminarily compensated frames are input into the enhancement module to obtain the final results.
Noteworthy is the introduction of Spatial-Temporal Look-up Tables (ST-LUTs), a pioneering method for querying both spatial and temporal dimensions simultaneously. This LUT structure enables the extraction of temporal information efficiently, marking a significant advancement in the field.
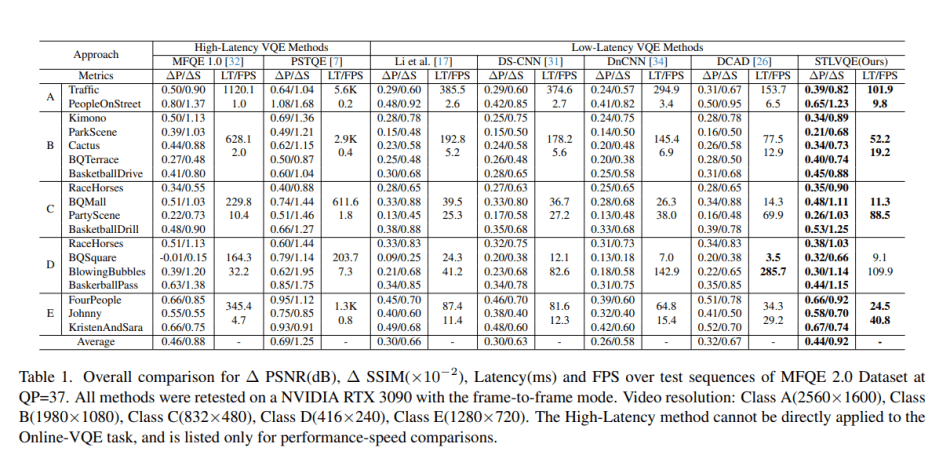
In empirical studies, the STLVQE network was compared to widely used single-frame methods and efficient multi-frame methods. STLVQE outperformed most low-latency VQE methods and achieved competitive performance with high-latency VQE methods, which are typically unsuitable for Online-VQE tasks. Impressively, STLVQE demonstrated real-time processing capabilities for 720P resolution videos, striking a favorable balance between enhancement performance and inference speed. As a result, the proposed STLVQE method stands as a pioneering solution to the challenges posed by real-time online video quality enhancement.
The paper Online Video Quality Enhancement with Spatial-Temporal Look-up Tables on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

The backrooms game typically features a minimalist approach to gameplay mechanics. Players navigate through a series of interconnected, often indistinguishable rooms, facing the challenge of staying oriented in an environment that seems purposefully designed to be disorienting. The game aims to evoke a sense of existential dread and fear of the unknown, with players unsure of what lurks around each corner.
Players must keep their bearings in a world that appears to be intentionally created to be disorienting as they make their way through a sequence of connected, frequently indistinguishable rooms. Since players may never be sure what will be around the corner, the game seeks to instill a sense of existential dread and terror of the unknown. buildnow gg