
In recent years, Large Language Models (LLMs) like ChatGPT and GPT-4 have achieved remarkable levels of performance in Natural Language Processing (NLP) tasks. Fine-tuning these models on high-quality instruction datasets further enhances their capabilities. However, existing methods for instruction data generation often suffer from issues such as duplicate data and insufficient control over data quality.
To address these challenges, in a new paper WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation, a Microsoft research team introduces CodeOcean, a dataset featuring 20,000 instruction instances across four universal code-related tasks. CodeOcean harnesses source code to explicitly control data quality, significantly improving the generalization ability of fine-tuned LLM models.

The primary focus of this work is on boosting the performance of code Large Language Models through instruction tuning. To explore the breadth of code-related tasks, the researchers select four tasks—Code Summarization, Code Generation, Code Translation, and Code Repair—that are universally representative and common across three generative tasks (code-to-text, text-to-code, and code-to-code).
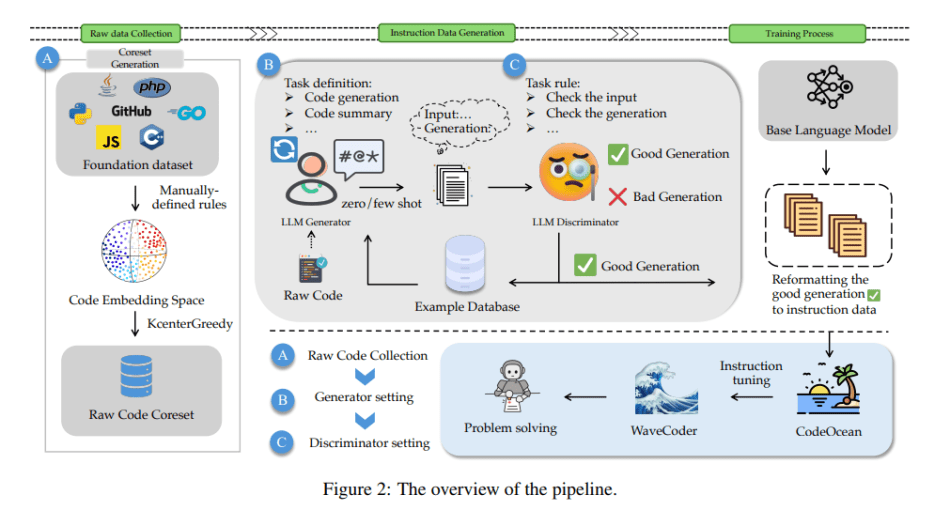
The process involves collecting raw code and then generating and reformatting instruction data for training. The team proposes a novel LLM-based Generator-Discriminator Framework capable of leveraging a vast amount of unsupervised open-source code to generate supervised instruction data. This approach ensures that the diversity of the generated data is not solely dependent on the capabilities of the teacher LLM itself.

In the generation phase, GPT-4 is utilized to generate a task definition within a specific scenario. The task definition and associated requirements are integrated into the generation prompt. Leveraging the few-shot abilities of GPT-3.5, the team uses raw code as input and selects good and bad case examples to generate the necessary knowledge for instruction tuning.
In the discriminator phase, a set of criteria related to instruction data is established, and GPT-4 is employed to assess the quality of instruction instances. Each instruction instance is classified as either a good or bad case, and this information is reused in the next generation as examples. This framework provides a comprehensive approach to generating and evaluating instruction data, ensuring a high-quality and diverse training dataset.
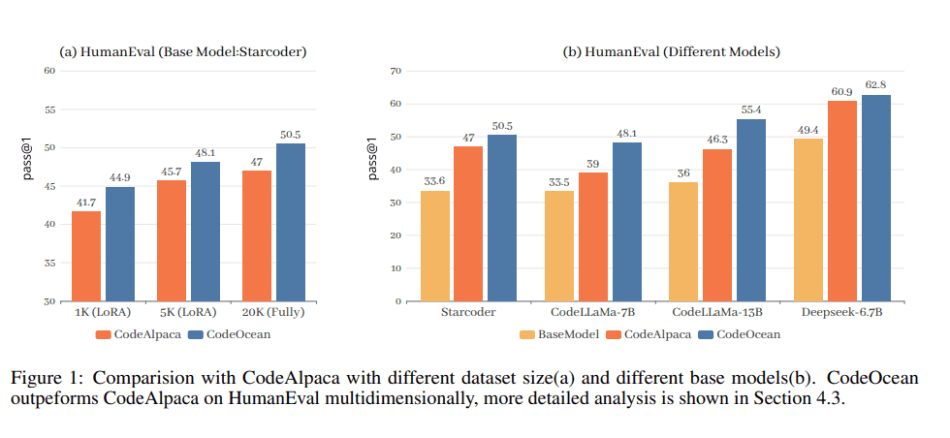
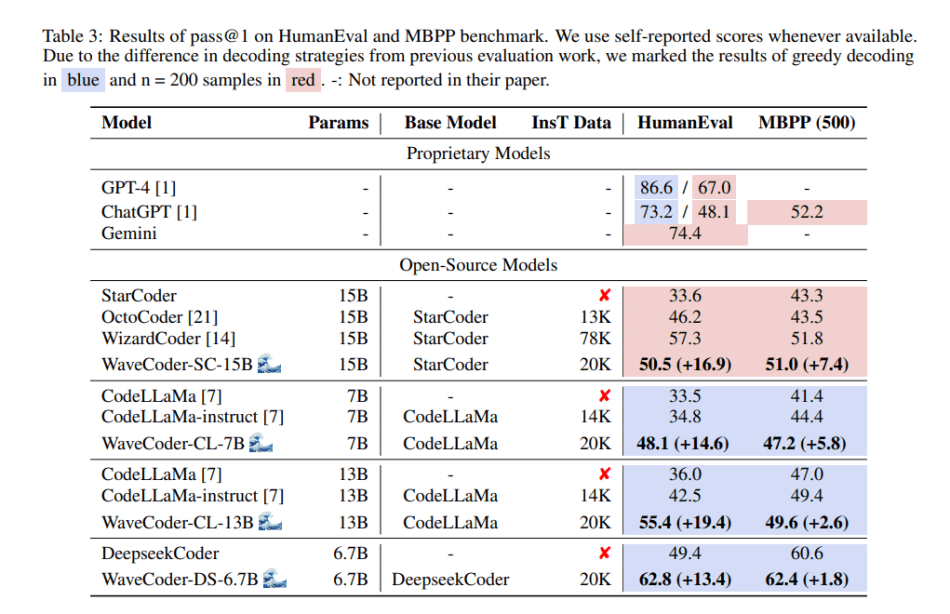
In the empirical study, the team evaluates WaveCoder on two code generation benchmarks: HumanEval and MBPP. The results demonstrate that WaveCoder models outperform instructed models even with fewer than 20K instruction tuning data. Additionally, refined and diverse instruction data significantly improves the efficiency of instruction tuning.
Overall, WaveCoder exhibits superior generalization ability compared to other open-source models in code repair and code summarization tasks. It maintains high efficiency on previous code generation benchmarks, underscoring its significant contribution to the field of instruction data generation and fine-tuning models.
The paper WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

0 comments on “Precision Coding Redefined: Microsoft WaveCoder’s Pioneering Approach to Fine-Tuned LLM Model Performance”