
The recent explosive growth of Large Language Models (LLMs) has showcased their exceptional performance across a spectrum of natural language processing tasks. However, this advancement comes with challenges, primarily stemming from their expanding size, which presents hurdles for deployment and sparks concerns regarding their environmental footprint and economic implications due to heightened energy demands.
In response to these challenges, one popular strategy involves leveraging post-training quantization to develop low-bit models for inference. This technique reduces the precision of weights and activations, thus substantially cutting down the memory and computational demands of LLMs. Additionally, recent exploration into 1-bit model architectures, exemplified by BitNet, offers a promising avenue for mitigating the costs associated with LLMs while upholding their performance standards.
Aligned with this trajectory, in a new paper The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, a research team from Microsoft Research and University of Chinese Academy of Sciences introduces a new variant of 1-bit LLMs called BitNet b1.58. This variant preserves the advantages of the original 1-bit BitNet while ushering in a novel computational paradigm that significantly enhances cost-effectiveness in terms of latency, memory usage, throughput, and energy consumption.

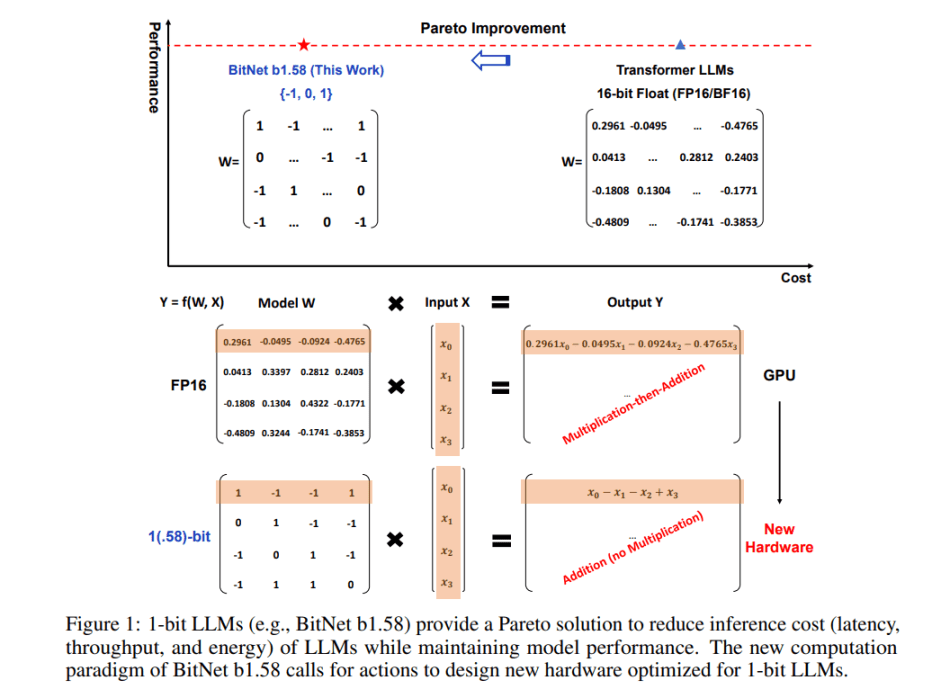
BitNet b1.58 builds upon the BitNet architecture, a Transformer model that substitutes nn.Linear with BitLinear. In this iteration, every parameter is ternary, assuming values of {-1, 0, 1}. The addition of an extra value, 0, to the original 1-bit BitNet results in 1.58 bits in the binary system.
Compared to its predecessor, BitNet b1.58 incorporates several enhancements:
- Quantization Function: The research team adopts an absmean quantization function, which proves more convenient and straightforward for both implementation and system-level optimization, while introducing negligible performance impacts in experiments.
- LLaMA-alike Components: BitNet b1.58 integrates LLaMA-alike components, employing RMSNorm, SwiGLU, rotary embedding, and eliminating all biases. This design facilitates seamless integration into popular open-source software with minimal effort.
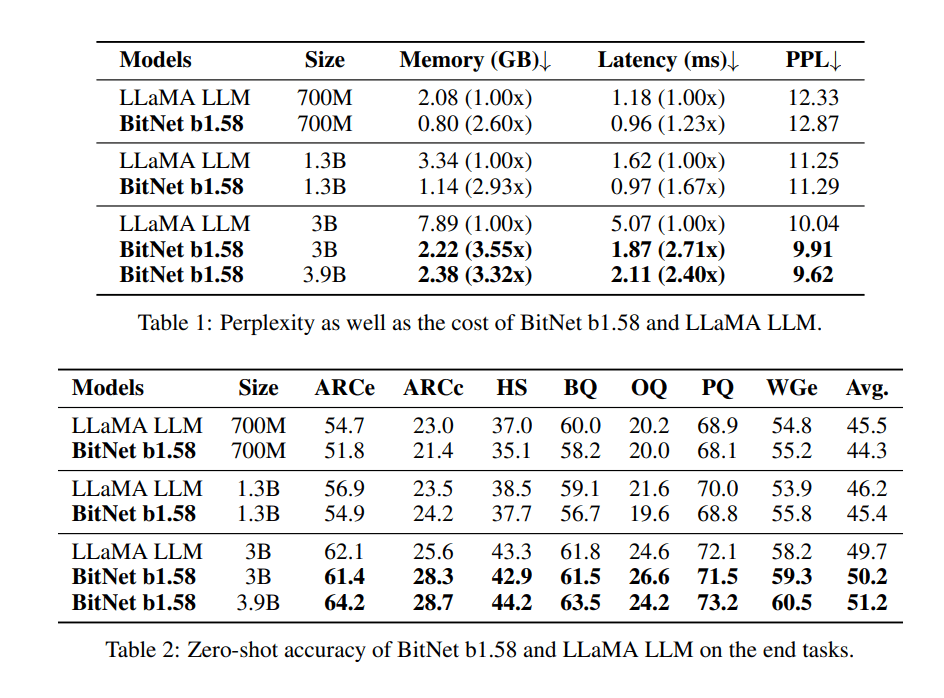
The researchers conducted comparative evaluations of BitNet b1.58 against FP16 LLaMA LLM across various sizes. Results indicate that BitNet b1.58 begins to match the performance of full-precision LLaMA LLM at a model size of 3B in terms of perplexity, while exhibiting 2.71 times faster performance and utilizing 3.55 times less GPU memory.
Moreover, BitNet b1.58 retains the key benefits of the original 1-bit BitNet, including its innovative computation paradigm that requires minimal multiplication operations for matrix multiplication, thereby enabling high optimization. It also maintains equivalent energy consumption to the original 1-bit BitNet while vastly improving efficiency in terms of memory consumption, throughput, and latency.
Furthermore, BitNet b1.58 offers two additional advantages. Firstly, its modeling capability is strengthened by explicit support for feature filtering, facilitated by the inclusion of 0 in the model weights, which significantly enhances the performance of 1-bit LLMs. Secondly, experimental results demonstrate that BitNet b1.58 can match full-precision (i.e., FP16) baselines in both perplexity and end-task performance, starting from a 3B model size, using identical configurations.
In summary, BitNet b1.58 establishes a new scaling law and framework for training next-generation LLMs that are both high-performance and cost-effective. Moreover, it introduces a novel computational paradigm and lays the foundation for designing specialized hardware optimized for 1-bit LLMs.
The paper The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

Hello friends, I would like to share with you my impressions of the mel bet app review, after reviewing it I found out about the https://melbetid.app/ VIP programme which exceeded my expectations. Exclusive privileges and rewards for VIP members make the gaming experience truly special. From personalised bonuses to priority customer support, being part of the VIP programme adds an extra layer of excitement and value to my time spent on the platform. I highly recommend checking it out, as there’s a lot more information there.
Pingback: Embracing the Period of 1-Bit LLMs: Microsoft & UCAS’s BitNet b1.58 Redefines Effectivity - TechTonicTales