
Generative modeling of complex behaviors from labeled datasets has long been a significant challenge in decision-making. This entails modeling actions—continuous-valued vectors that exhibit multimodal distributions, often sourced from uncurated data. Errors in generation can compound, especially in sequential prediction scenarios.
To address this challenge, in a new paper Behavior Generation with Latent Actions, a research team from Seoul National University, New York University and Artificial Intelligence Institute of SNU introduces the Vector-Quantized Behavior Transformer (VQ-BeT). This innovative model offers a solution for behavior generation, addressing multimodal action prediction, conditional generation, and partial observations. VQ-BeT not only demonstrates enhanced capability in capturing diverse behavior modes but also accelerates inference speed by a factor of 5 compared to Diffusion Policies.

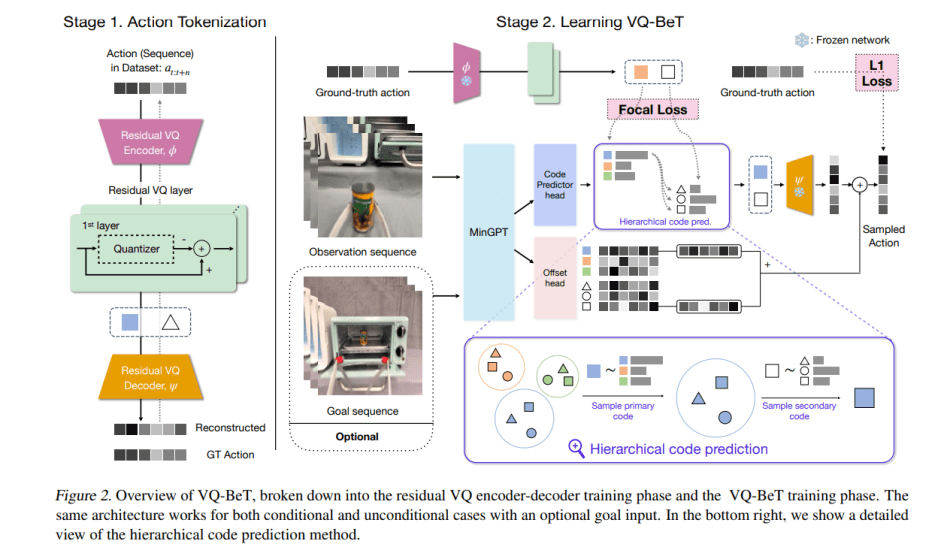
VQ-BeT’s versatility makes it suitable for both conditional and unconditional generation tasks, with applications spanning simulated manipulation, autonomous driving, and real-world robotics. The model comprises two key stages: the Action Discretization phase and the VQ-BeT Learning phase. In the former, a Residual Vector-Quantized Variational Autoencoder (Residual VQ-VAE) is employed to learn a scalable action discretizer, crucial for dealing with the complexity of real-world action spaces. The latter phase involves training a GPT-like transformer architecture to model the probability distribution of actions or action sequences from observations.
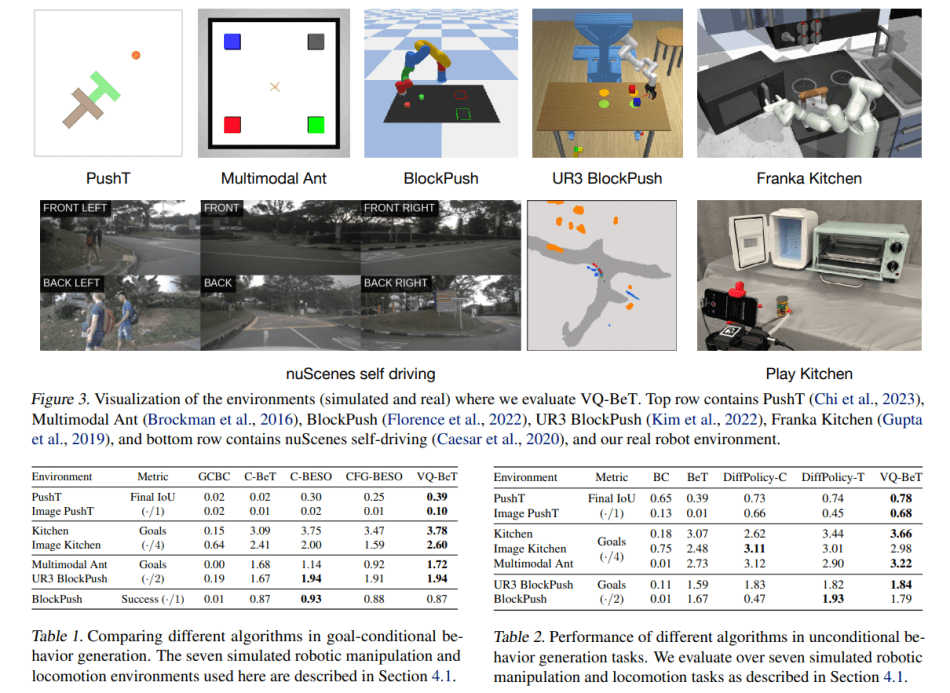
In their empirical study, the team conducted experiments across eight benchmark environments, yielding several notable insights:
- VQ-BeT achieves state-of-the-art (SOTA) performance in unconditional behavior generation, outperforming BC, BeT, and diffusion policies in 5 out of 7 environments.
- For conditional behavior generation, by specifying goals as input, VQ-BeT achieves SOTA performance, surpassing GCBC, C-BeT, and BESO in 6 out of 7 environments.
- VQ-BeT exhibits promising performance on autonomous driving benchmarks such as nuScenes, matching or even surpassing task-specific SOTA methods.
- Being a single-pass model, VQ-BeT offers a substantial speedup, achieving 5 times faster inference in simulation and 25 times faster on real-world robots compared to multi-pass models utilizing diffusion models.
- VQ-BeT demonstrates scalability to real-world robotic manipulation tasks such as object pick-and-place and door closing, showing a 73% improvement on long-horizon tasks compared to previous approaches.
In summary, VQ-BeT excels across various manipulation, locomotion, and self-driving tasks. An exciting prospect lies in scaling up these models to large behavior datasets containing significantly more data, environments, and behavior modes.
The paper Behavior Generation with Latent Actions is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

Pingback: Quick Tracks to Numerous Behaviors: VQ-BeT Achieves 5x Velocity Surge In comparison with Diffusion Insurance policies - TechTonicTales