
Despite the remarkable capabilities of contemporary large language models like GPT-4, Claude 2, or Gemini, the inner mechanisms governing their operations remain shrouded in mystery. While the intricate details of these models are kept under wraps, they are made accessible through APIs, prompting the question: How much insight can adversaries glean about these models by interacting with their APIs?
To answer this question, in a new paper Stealing Part of a Production Language Model, a research team from Google DeepMind, ETH Zurich, University of Washington, OpenAI and McGill University introduces a groundbreaking model-stealing attack. This attack unveils precise, nontrivial information from black-box production language models such as OpenAI’s ChatGPT or Google’s PaLM-2.

Model-stealing attacks, as outlined by Tramèr et al. (2016), aim to decipher the functionality of black-box models, primarily optimizing for accuracy and fidelity. This study, however, zeroes in on high-fidelity attacks, particularly focusing on black-box language models. The proposed method enables the recovery of the complete embedding projection layer of a transformer language model.

Unlike previous approaches that reconstruct models from the bottom-up, commencing from the input layer, this method takes a top-down approach by directly extracting the model’s last layer. Leveraging the characteristic of the final layer projecting from the hidden dimension to a logit vector, which inherently possesses low-rank properties, targeted queries to the model’s API unveil crucial insights such as the embedding dimension or the final weight matrix.
Stealing this pivotal layer offers several advantages:
- It discloses the width of the transformer model.
- It marginally diminishes the opacity of the model, rendering it less of a complete “black box.”
- It provides broader insights into the model, including relative size differences among various models.
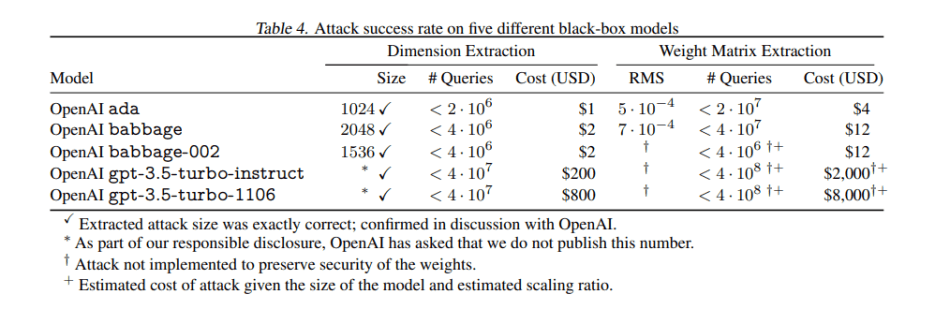
In their empirical investigation, the proposed attack remarkably extracts the entire projection matrix of OpenAI’s ada and babbage language models for under $20 USD. Additionally, the team successfully recovers the exact hidden dimension size of the gpt-3.5-turbo model. Estimations suggest that under $2,000 worth of queries would suffice to recover the entire projection matrix of this model.
The paper Stealing Part of a Production Language Model is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

Pingback: First Mannequin-Stealing Assault Reveals Secrets and techniques of Black-Field Manufacturing Language Fashions