
Understanding sound is undeniably crucial for an agent’s interaction with the world. Despite the impressive capabilities of large language models (LLMs) in comprehending and reasoning through textual data, their grasp of sound remains limited.
In their recent paper titled “Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities,” a team of researchers from NVIDIA introduces Audio Flamingo, a groundbreaking audio language model. This model incorporates in-context learning (ICL), retrieval augmented generation (RAG), and multi-turn dialogue capabilities, achieving state-of-the-art performance across various audio understanding tasks.

The team summarizes their key contributions as follows:
- We propose Audio Flamingo: a Flamingo-based audio language model for audio understanding with a series of innovations. Audio Flamingo achieves state-of-the-art results on several close-ended and open-ended audio understanding tasks.
- We design a series of methodologies for efficient use of ICL and retrieval, which lead to the state-of-the-art few-shot learning results.
- We enable Audio Flamingo to have strong multiturn dialogue ability, and show significantly better results compared to baseline methods.
The Audio Flamingo architecture is composed of four components: i) an audio feature extractor with sliding window, ii) audio representation transformation layers, iii) a decoder-only language model, and iv) gated xattn-dense layers.
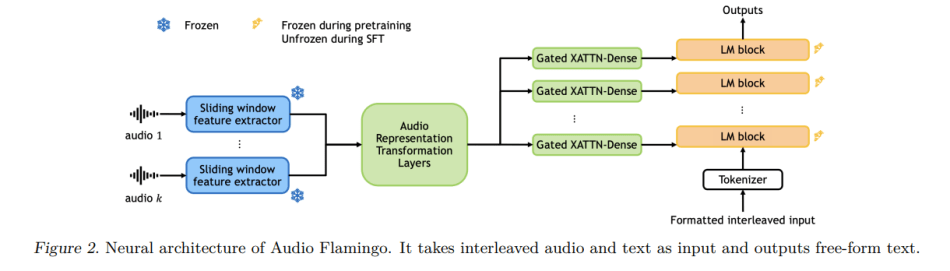
Specifically, the team utilizes ClapCap (Elizalde et al., 2023b) as the backbone for the audio feature extractor, processing 7-second, 44.1kHz raw audio inputs into a 1024-dimensional vector representation. For longer audio segments, they employ sliding windows to capture temporal information effectively.
The audio representation transformation layers consist of three self-attention layers with 8 heads and an inner dimension of 2048 each. For the language model, they employ OPT-IML-MAX-1.3B (Iyer et al., 2022), a model with 1.3 billion parameters and 24 LM blocks. They integrate gated xattn-dense layers from Flamingo to condition the model on audio inputs.
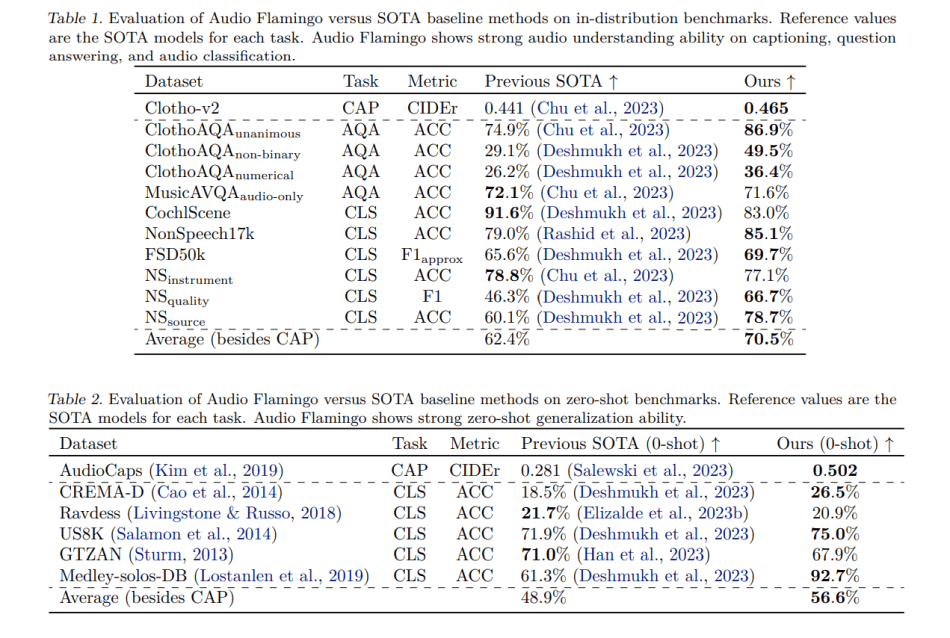
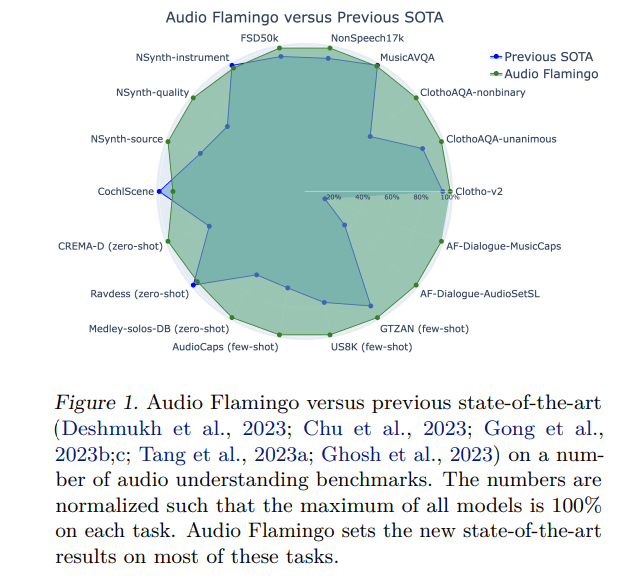
The researchers evaluated Audio Flamingo across a diverse range of close and open-ended benchmarks. A single Audio Flamingo model outperforms previous state-of-the-art systems on most benchmarks, with the dialogue version significantly surpassing baseline performance on dialogue tasks.
The team intends to open-source both the training and inference code for Audio Flamingo, with a demo website available at https://audioflamingo.github.io/.
The paper Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

Pingback: Introducing NVIDIA’s Audio Flamingo, The Next Frontier In Audio Language Models
Balancing work and studies has been a challenge, but discovering a service that writes essays for money was a lifesaver. Their team understood my requirements perfectly and delivered essays that exceeded my expectations. The convenience and efficiency of https://domyessay.com/write-essays-for-money helped me maintain my grades without sacrificing my job commitments. It’s a great resource for anyone looking to manage their academic workload more effectively.