
Recent advancements in language model pre-training draw inspiration from Chinchilla scaling laws, advocating for scaling data alongside model size within a fixed compute budget. This approach presents a compelling trade-off, allocating compute resources towards training on more extensive datasets rather than simply increasing model size. Such a strategy reduces latency and compute requirements for model deployment, driving significant developments in language modeling training methodologies.
In line with this trend, in a new paper Nemotron-4 15B Technical Report , an NVIDIA research team introduces Nemotron-4 15B. Nemotron-4 15B is comprising 15 billion parameters, is trained on an extensive corpus of 8 trillion text tokens, showcasing unparalleled multilingual capabilities among models of comparable size.

Nemotron-4 employs a standard decoder-only Transformer architecture (Vaswani et al., 2017) with causal attention masks. It consists of 3.2 billion embedding parameters and 12.5 billion non-embedding parameters, incorporating innovative techniques such as Rotary Position Embeddings (RoPE) (Su et al., 2021), SentencePiece tokenizer (Kudo and Richardson, 2018), squared ReLU activations in MLP layers, no bias terms, dropout rate of 0, and untied input-output embeddings. Additionally, the model utilizes Grouped Query Attention (GQA) (Ainslie et al., 2023) to enhance inference speed and reduce memory footprint.
Training Nemotron-4 involved utilizing 384 DGX H100 nodes, each equipped with 8 H100 80GB SXM5 GPUs based on the NVIDIA Hopper architecture (NVIDIA, 2022). The researchers employed a combination of 8-way tensor parallelism (Shoeybi et al., 2019) and data parallelism, along with a distributed optimizer to shard the optimizer state over data-parallel replicas.
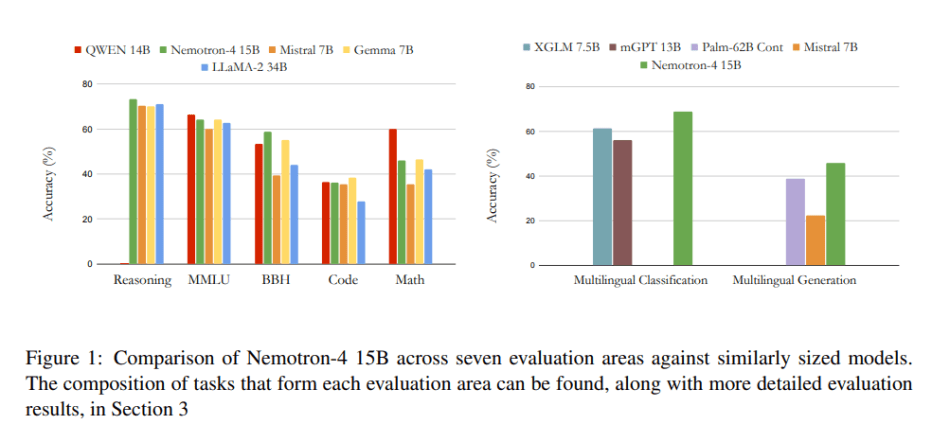
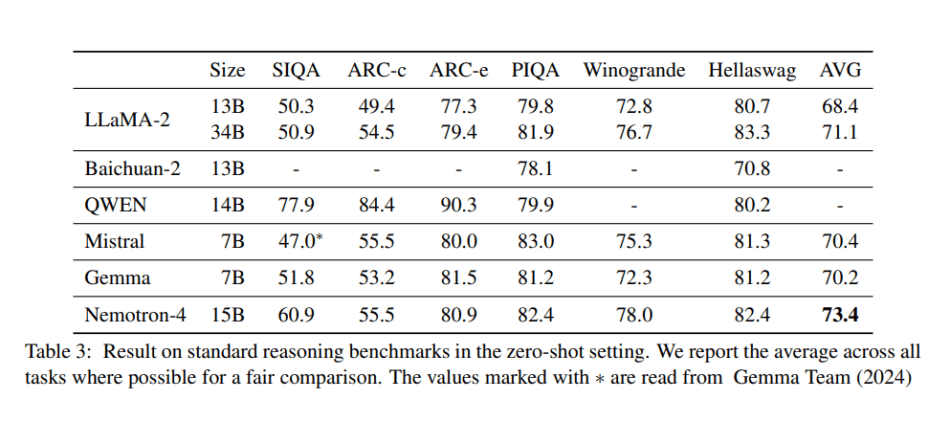
Nemotron-4 15B achieves exceptional downstream accuracies across various domains, including English, code, and multilingual evaluations. Notably, it surpasses models over four times larger and those explicitly tailored for multilingual tasks, establishing itself as the leader in multilingual capabilities among models of similar scale.
In summary, Nemotron-4 15B demonstrates unparalleled multilingual performance among general-purpose language models at its scale, even outperforming specialized models in the multilingual domain. Its success underscores the potential for large language models to be pre-trained on extensive token corpora, yielding remarkable outcomes.
The paper Nemotron-4 15B Technical Report is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

Improve the comfort and privacy of your space with professional window tinting from WFI. Our durable films are designed to block harmful UV rays, reduce heat, and add a stylish touch to your windows. Learn more about our range of windows tint solutions and schedule your installation with our experienced team.