Large language models (LLMs) have demonstrated remarkable proficiency in various natural language tasks and an impressive ability to follow open-ended instructions, showcasing strong generalization capabilities. Despite these successes, a notable limitation of LLMs is their inability to perceive non-textual modalities such as audio.
In a new paper SpeechVerse: A Large-scale Generalizable Audio Language Model, a research team from Amazon AWS AI Labs introduces SpeechVerse, a robust multi-task framework that leverages supervised instruction fine-tuning to achieve strong performance across various speech tasks.

The team summarizes their main contributions as follows:
- Scalable Multimodal Instruction Fine-tuning: SpeechVerse is a novel LLM-based audio-language framework designed to deliver strong performance across 11 diverse tasks. The team extensively benchmarks their models on public datasets covering ASR, spoken language understanding, and paralinguistic speech tasks.
- Versatile Instruction-Following Capability: The SpeechVerse model leverages the robust language understanding of its LLM backbone to adapt to open-ended tasks that were not included during multimodal fine-tuning.
- Strategies for Improved Generalization: The team explores prompting and decoding strategies, including constrained and joint decoding, which enhance the model’s ability to generalize to completely unseen tasks, improving absolute metrics by up to 21%.
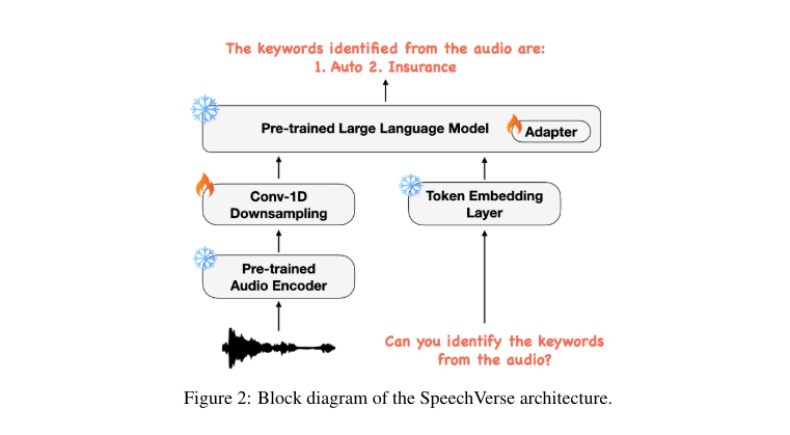
The proposed multimodal model architecture comprises three main components:1) A pre-trained audio encoder that encodes audio signals into feature sequences. 2) A 1-D convolution module that shortens the audio feature sequence. 3) A pre-trained LLM that uses these audio features and textual instructions to perform the required tasks.
The researchers developed three variants of multimodal models using the SpeechVerse framework: 1) Task-FT: A set of models where each model is trained individually for a specific task. 2) Multitask-WLM: A single multi-task model trained by pooling datasets for all tasks together. 3) Multitask-BRQ: Similar to Multitask-WLM, but using the Best-RQ architecture for the audio encoder.
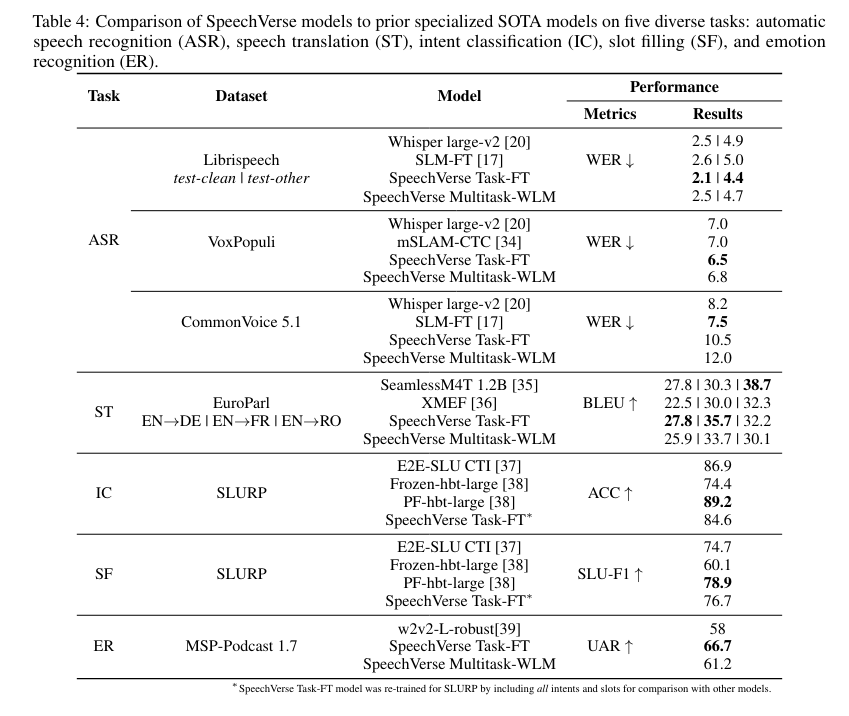
In their empirical study, the researchers compared their models with a cascaded baseline that uses an LLM on ASR hypotheses. SpeechVerse outperformed conventional baselines on 9 out of 11 tasks, maintaining robust performance on out-of-domain datasets, unseen prompts, and even unseen tasks.
Looking ahead, the researchers plan to enhance SpeechVerse’s
capabilities to follow more complex instructions and generalize
to new domains. By decoupling task specification from model
design, SpeechVerse represents a versatile framework capable of
dynamically adapting to new tasks through natural language
without the need for retraining.
The paper
SpeechVerse: A Large-scale Generalizable Audio Language Model is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

At Smash House, every burger is crafted to perfection, offering a delicious and satisfying meal every time. The restaurant’s inviting atmosphere makes it perfect for any occasion, whether you’re dining solo or with a group. For more information on their mouthwatering burgers and other menu items, be sure to visit their website.