
Transformers have fundamentally transformed the field of natural language processing, driving significant advancements across numerous applications. With their widespread success, there is a growing interest in understanding the complex mechanisms of these models. One key aspect that has not been thoroughly examined is the inherent linearity of intermediate embedding transformations within transformer architectures.
In a new paper Your Transformer is Secretly Linear, a research team from AIRI, Skoltech, SberAI, HSE University, and Lomonosov Moscow State University reveals a nearly perfect linear relationship in transformations between sequential layers. They also introduce an innovative distillation technique that replaces certain layers with linear approximations while maintaining model performance.


The team investigates the extent of linearity and smoothness in transformations between sequential layers and finds an unexpectedly high degree of linearity in embedding transformations. By examining how linearity evolves throughout model training, they observe a significant trend: during pretraining, the average linearity of the main stream decreases.
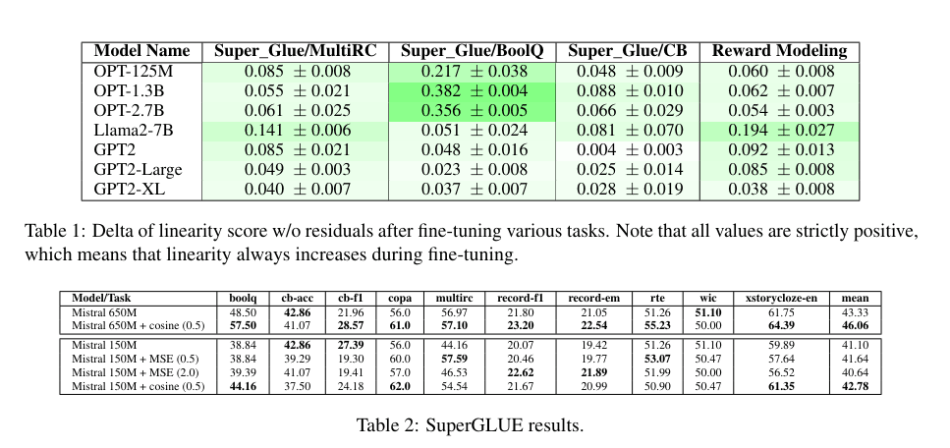
In contrast to the decreasing linearity during pretraining, all models studied exhibit an increase in linearity during fine-tuning. This suggests that fine-tuning for specific tasks tends to enhance and amplify the linear properties of transformer models.
Building on these findings, the researchers present a novel distillation technique that involves pruning and replacing certain layers with linear approximations, followed by distilling layer-wise embeddings to retain model performance. They also introduce a new regularization method for pretraining based on cosine similarity, aimed at reducing layer linearity. This approach not only improves the performance of transformer models on benchmarks like Tiny Stories and SuperGLUE but also enhances the expressiveness of embeddings.
In summary, this study challenges the current understanding of transformer architectures by providing a detailed examination of linearity within transformer decoders, revealing their inherent near-linear behavior across various models. The proposed methods offer a path toward more computationally efficient transformer architectures without compromising their effectiveness.
The code is available on project’s GitHub. The paper Your Transformer is Secretly Linear is on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.

In the bustling heart of Manhattan, our classic barber shop at 299 East 52nd Street stands as a sanctuary of style and sophistication. Our barbershop combines the timeless traditions of classic barbering with contemporary techniques, offering an unparalleled grooming experience for discerning gentlemen. Whether you’re seeking a precision haircut, a relaxing shave, or expert beard care, our barbershop is dedicated to making you look and feel your absolute best.